基础架构
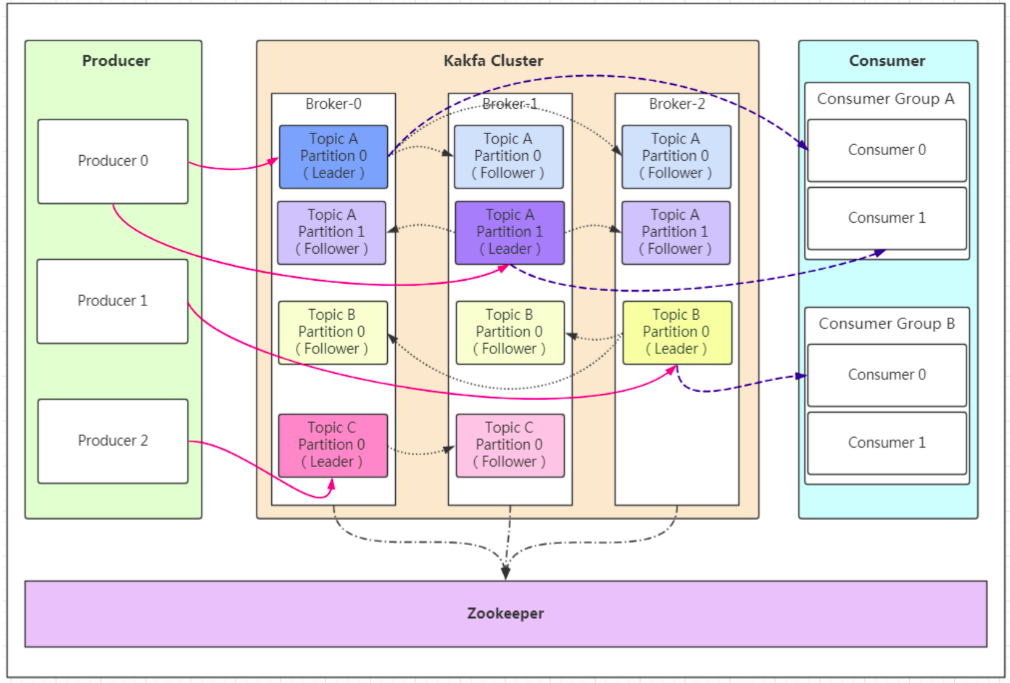
producer 生产者,消息产生
broker 实例对应服务器的节点,每个cluster集群内的broker都有不重复的编号
topic 消息主题,分类
partition topic的分区,用作负载,提高吞吐量,对应的是一个个文件
replication 分区副本,作用是备份,主leader故障,follower进行选主,副本数不大于broker数,主备不在同一个机器,同一机器对同一分区也只放一个副本
message 消息的主体
consumer 消费者
consumer group 消费者组 同一个分区只能被某一组消费者消费
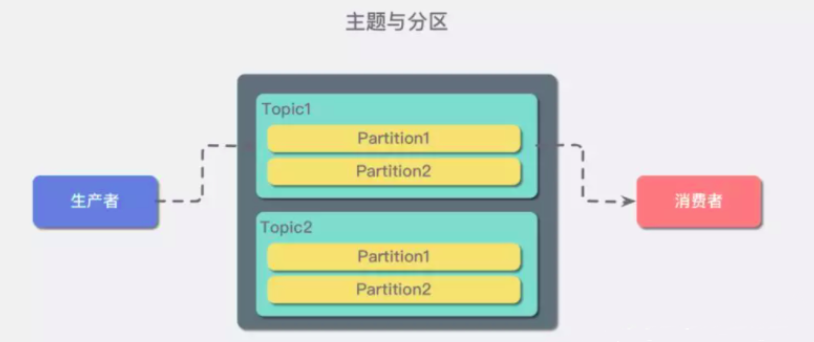
主题 分区 集群
增加分区partition,提高消费效率
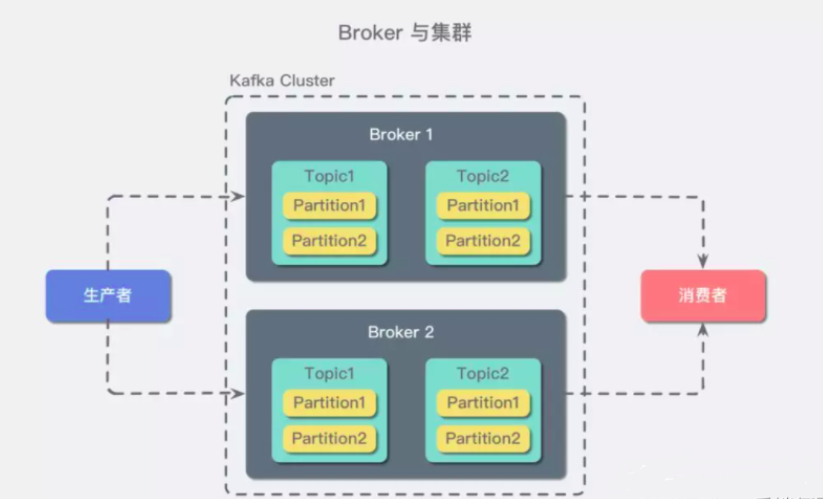
多实例broker,在但节点故障时增加容错率
retention 消息的保留机制
- log.retention.hours
- log.retention.minutes
- log.retention.ms 优先级最高
1 | grep -i 'log.retention.[hms].*\=' config/server.properties |
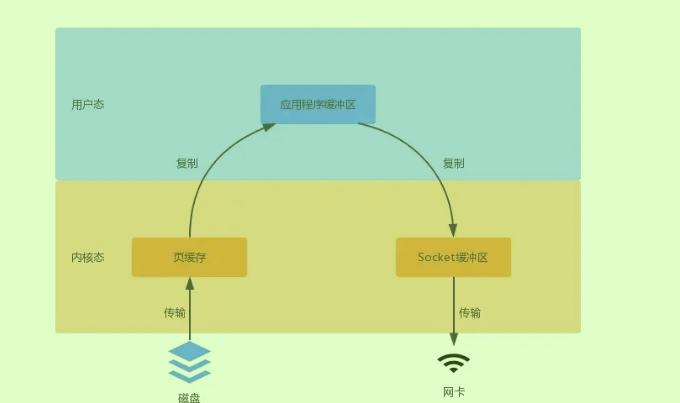
效率
磁盘顺序读写
零拷贝而言,并非是真的没有数据拷贝的过程,只不过是减少了用户态和内核态的切换次数,以及CPU的拷贝次数
1 | #可以将文件内容直接发送到网络输出流中 |
mmap()是一个用于创建内存映射的系统调用函数
1 | void *mmap(void *addr, size_t length, int prot, int flags, int fd, off_t offset); |
成功时返回映射区域的起始地址;
失败时返回MAP_FAILED(通常是(void *)-1)
重复消费
消息重复消费和消息丢包的解决办法
保证不丢失消息:生产者(ack=all 代表至少成功发送一次) 重试机制
消费者 (offset手动提交,业务逻辑成功处理后,提交offset)
保证不重复消费:落表(主键或者唯一索引的方式,避免重复数据)
业务逻辑处理(选择唯一主键存储到Redis或者mongdb中,先查询是否存在,若存在则不处理;若不存在,先插入Redis或Mongdb,再进行业务逻辑处理)
保证数据不会丢失的问题
- 1.producter端通过ack机制保证数据不丢失
- 2.broker端通过topic副本数保证数据不丢失,同时要求生产端ack为-1
- 3.consumer端通过提交偏移量offset来保证数据不丢失,但是可能会导致重复消费
重复消费已经消费过的数据,可以使用以下两种方法:
- 更改消费者组:如果你使用的是相同的消费者组,那么 Kafka 将会将已经被消费的消息排除在消费者组之外,从而避免重复消费。因此,你可以更改消费者组的名称,从而允许消费者重新消费之前已经消费过的消息。
- 设置消费者的偏移量:Kafka 中每个分区的消息都有一个偏移量,表示消息在分区中的位置。消费者可以通过设置偏移量来重新消费之前已经消费过的消息。你可以通过重置消费者的偏移量,将其设置为之前已经消费过的消息的偏移量,从而允许消费者重新消费这些消息。
